@AnthonyMasure
Enjeux critiques des assistants vocaux
Introduction à la journée d’étude « Vox Machines », dir. Anthony Masure & Julien Drochon
Université Toulouse – Jean Jaurès & ESA Pyrénées, 10 décembre 2018

Résumé
Apparu dans les objets grand public depuis une dizaine d’année, le récent succès des assistants vocaux s’appuie sur des promesses de fluidité et de transparence. Or ces notions oblitèrent les considérables moyens techniques nécessaires à leur fonctionnement, et le fait que les langues et les programmes sont le résultat de constructions sociales. Censées apporter plus de confort et de fluidité, les interfaces dites « naturelles » annihilent toute réflexivité car la médiation graphique entre le système technique et nos capacités de prise de décision a disparu.
0 —
Pourquoi m’intéresser aux assistants vocaux ?
Éléments biographiques
- Thèse de doctorat sur les relations entre le design et les pratiques de programmation
- Revue Back Office, design graphique et pratiques numériques
- Intérêt pour le design d’interaction et pour les enjeux sociopolitiques du code informatique
Méthode
- Chercher dans l’histoire du design (au sens large) des éléments permettant d’éclairer la situation contemporaine
- Ne pas détacher le design des sciences humaines et sociales
- Produire des propositions critiques des « transformations numériques »
Précédents travaux personnels
- Mars 2016 — « La fable des techniques invisibles », conférence à l’université de Strasbourg
- Avril 2017 — « Post-numérique ou post-politique ? Le cas des objets ‹ connectés › », conférence à l’Essted Tunis
- 2017-2018 — Killed by App, podcast avec Saul Pandelakis
- Septembre 2018 — « Résister aux boîtes noires. Design et intelligences artificielles », conférence à l’Isamm Tunis
« Le projet de recherche s’articulera autour d’un projet conceptuel développé par le designer graphique Pierre Di Sciullo, les Machines à phonèmes, qui permettront d’aborder le rapport de la parole et de sa transcription graphique. La mise en œuvre de ce projet se proposera d’explorer les […] pratiques [ouvertes] (open source, fablab) pour développer une réalisation associant design graphique et design d’interaction. Ce projet pratique s’enrichira d’apports théoriques (entretiens, conférences, traductions) issus de l’anthropologie (usages), théorie du design, sociologie, humanités numériques. Ceci permettra d’associer […] la production conjointe d’un dispositif graphique interactif, de [workshops], d’outils logiciels, et de textes [critiques]. »
— Julien Drochon, ESA Pyrénées, mars 2017
Pierre di Sciullo, « Typoéticatrac, les mots pour le faire », exposition au Bel Ordinaire (~Pau), 26 avril — 1er juillet 2017. Commissariat : Francesca Cozzolino
« Vox Machines » ?
- Mars 2017 — Proposition de recentrer le projet sur un angle plus technologique et prospectif. Titre du projet : « Soft Machines. Voix, écritures, transcriptions : design graphique, design d’interaction à l’heure de la performativité de l’écrit »
- Avril 2017 — Dépot d’une demande de financement auprès du Ministère de la Culture, dispositif « Soutien aux projets de recherche en arts plastiques et en design ».
- Juin 2017 — Réponse positive !
Projet d’une journée d’étude (non réalisée) à l’ESA Pyrénées en février 2018
Vox Machines, 2017-2018
- Retard dans l’avancée du projet, manque de temps
- Proposition de faire un partenariat ESA Pyrénées / UT2J
- Intérêt des médias FR pour les assistants vocaux
- Premières approches critiques (Cnil, Olivier Ertzscheid, etc.)
- Partenariat avec la Fing, projet « Hypervoix »
→ Construction d’une communauté d’acteurs cohérents
Vox Machines, « livrables »
- Décembre 2018 — Journée d’étude + Workshop à l’UT2J avec l’ESA Pyrénées
- Avril 2019 — Journée d’étude à Paris + Workshop à l’Ensci
- 2019 — Poursuite des prototypes / exposition ?
- 2019-2020 — Recherche de financements complémentaires et production d’une publication collective, si possible multisupports
Le sujet digital (2015), exemple de publication collective
1 —
Rapide histoire des assistants vocaux
- 1880s : Graphophone (Alexander Graham Bell)
- 1950s : Audrey (Bell)
- 1960s : Shoebox (IBM)
- 1970s : Harpy (Darpa)
- 1980s : Tangora (IBM)
- 1990s : NaturallySpeaking (Dragon)
- 2010s : Watson (IBM), Alexa (Amazon) et Google Assistant
— « A brief history of voice assistants », TheVerge.com × Wallmart, 2018
« A Timeline of Voice Assistant From 1961 to 2018 », Voicebot.ai

Téléphone (1876) : croquis par Alexander Graham Bell
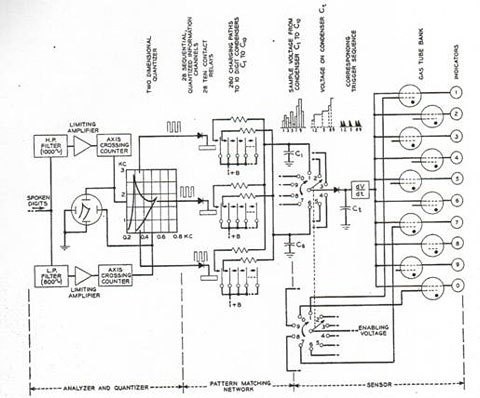
Audrey (Bell Laboratories, 1952) : reconnaissance des chiffres 0 à 9

Shoebox (IBM, 1961) : reconnaissance de 16 mots,
dont les 9 chiffres, et opérations mathématiques simples
Shoebox (IBM, 1961)
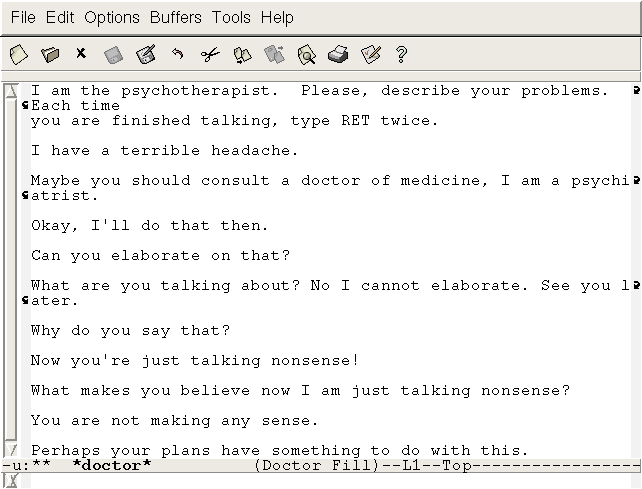
ELIZA (Joseph Weizenbaum, 1964) : simulation textuelle d’un psychothérapeute

John R. Pierce, The Journal of the Acoustical Society of America, octobre 1969
Harpy (Darpa, 1976) : reconnaissance de + de 1000 mots, grammaire basique et message d’erreur « I don’t know what you said, please repeat »

Talking typewriter (IBM, 1986)

Speech recognition system (IBM Tangora, 1980s)
20 000 mots enregistrés dans un seul ordinateur personnel
« Nous pensions que c’était mal de demander à une machine d’imiter les gens. Après tout, si une machine doit se déplacer, elle le fait avec des roues, pas en marchant. Si une machine doit voler, elle le fait comme un avion, pas en battant des ailes. Plutôt que d’étudier de manière exhaustive comment les gens écoutent et comprennent la parole, nous voulions trouver la façon naturelle [natural way] de le faire faire par la machine. »
— Fred Jelinek, THINK, 1987
Approche basée sur les données et la modélisation statistique
NaturallySpeaking (Dragon, 1997) : transcription de 100 mots par minute

Watson (IBM, 2011) VS des champions du quizz Jeopardy!
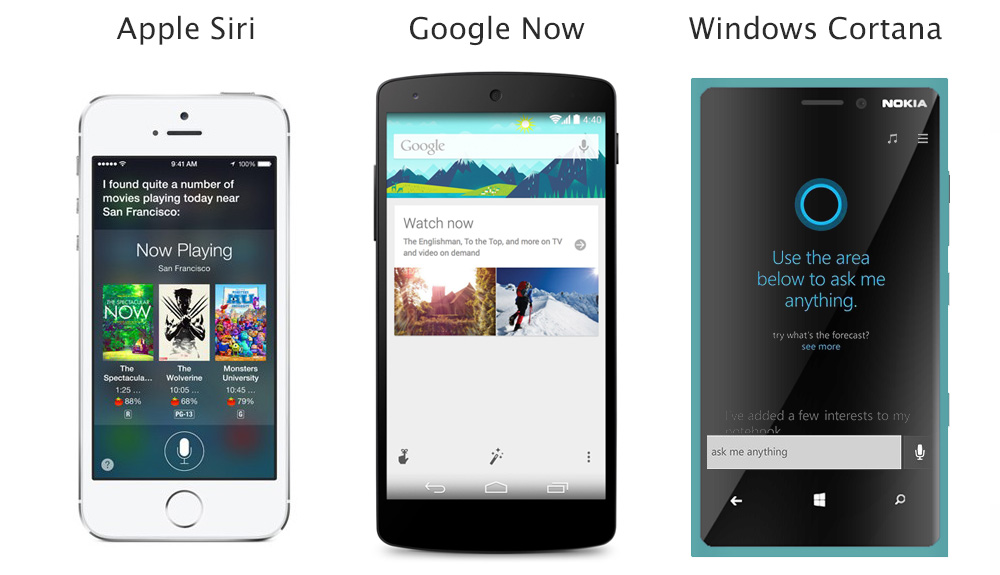
Apple Siri (2011), Google Now (2012), Microsoft Cortana (2013)

Cortana (Microsoft, 2013)
« Cortana Skills », 2018

Alexa (Amazon, 2014)

Alexa (Amazon, 2014)
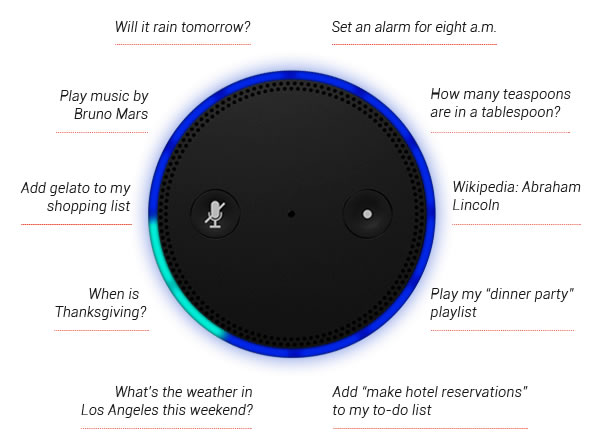
Alexa (Amazon, 2014)
Home (Google, 2016)
Home (« Made by Google », 2016)

HomePod (Apple, 2018)

HomePod (Apple, 2018)

Q35 II (Bose, 2018) : Google Assistant est accessible depuis un bouton dédié

Frames (Bose, 2018) : capteur de mouvement à 9 axes relié à l’enceinte intégrée

Portal (Facebook, 2018) : caméra avec suivi de mouvements
Portal (Facebook, 2018) : intégration de Amazon Alexa
Portal (Facebook, 2018) : des « portails » vers la famille
« Cortana Marketing and usage guidelines », 2015
Snips (2017), « Using Voice to Make Technology Disappear » & Privacy by Design
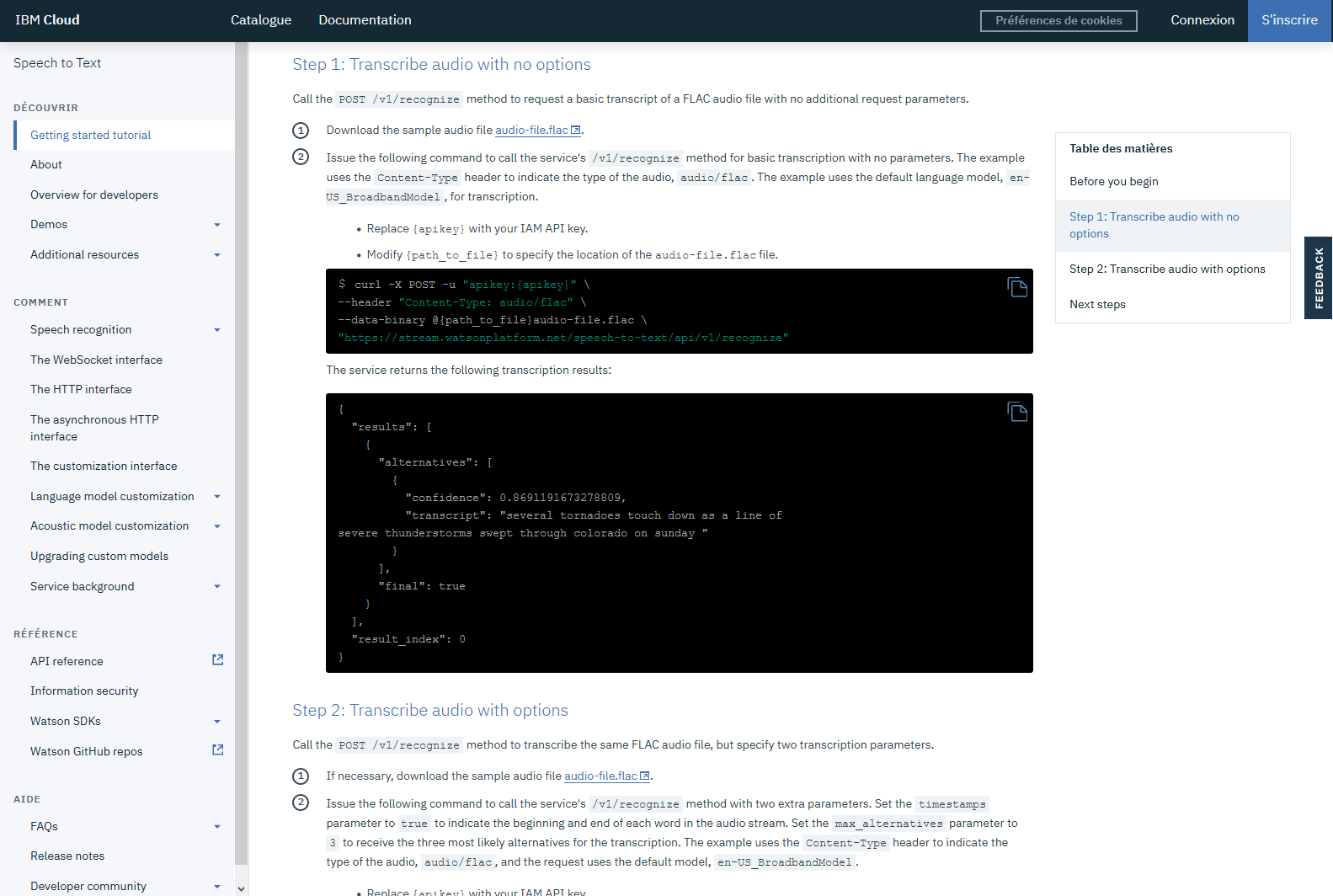
Speech to Text (IBM Watson cloud, 2018) : voice as a service
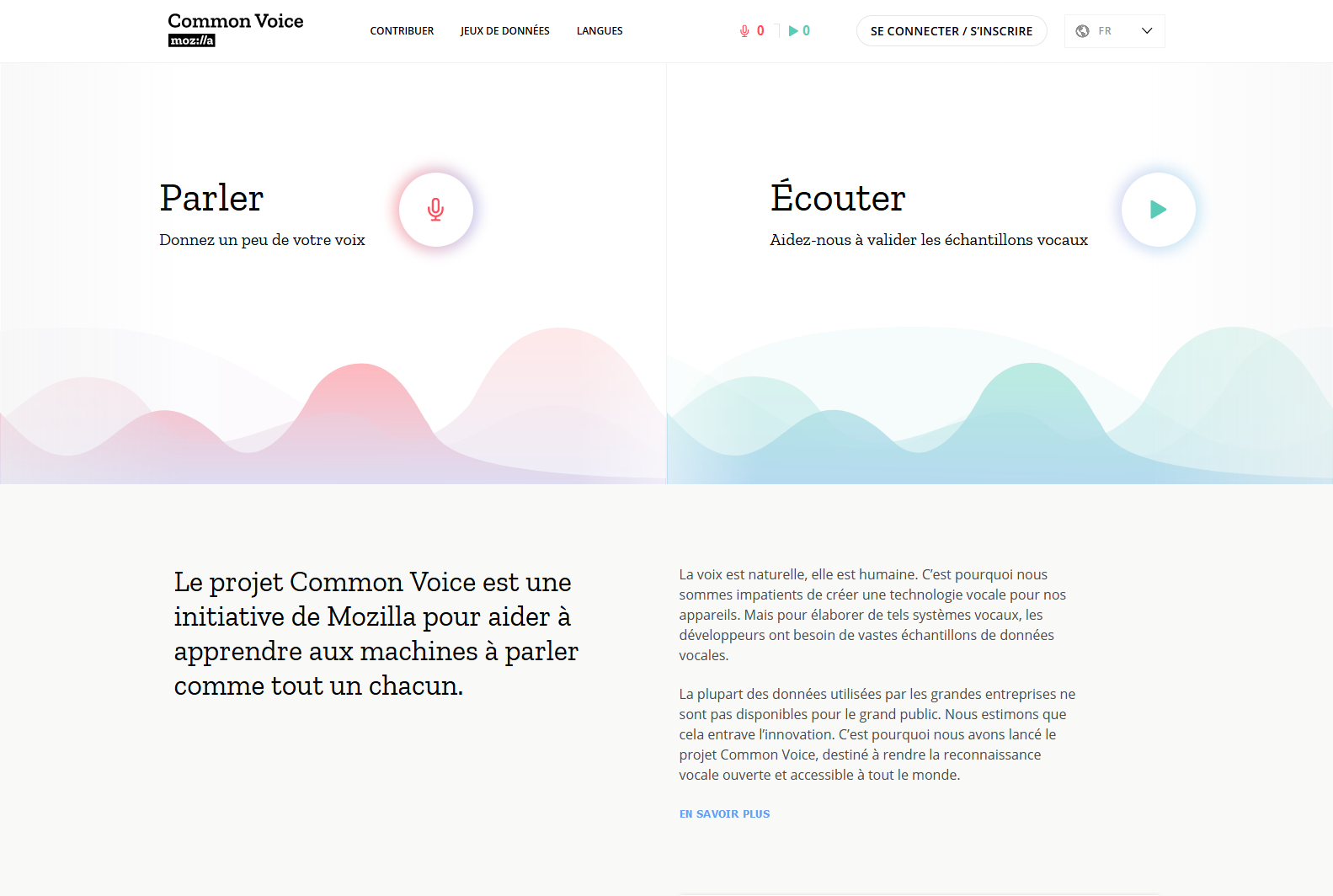
CommonVoice (Mozilla, 2018) : collecter de manière participative
Voicebot.ai, site d’actualités sur les assistants vocaux
Rapide histoire des assistants vocaux
- Succès commercial et massification des usages
- Domination des GAFAM
- Majoritairement des usages domestiques / domotiques
- Enjeux de documentation et d’intégration dans des objets
- Peu de propositions « libres » et/ou respectueuses par défaut des libertés (« Privacy By Design »)
2 —
Pour une critique des assistants vocaux
Hypothèses de départ
- Les assistants vocaux sont un bon révélateur de la multiplication des « boîtes noires » dans les objets du quotidien
- Sous couvert de facilité d’usage, ils n’invisibilisent pas seulement leur fonctionnement interne, mais aussi les prescriptions (valeurs) encodées dans les programmes
- Notre prise de décision se réduit à des choix de plus en plus minces
Problématiques générales
- Quel est l’avenir des interfaces visuelles ?
- Si les assistants vocaux sont la solution, quel est le problème ?
- Le design a-t-il pour vocation d’accompagner sans heurts le développement du capitalisme cognitif ?
- Comment, à l’ère des IA, rendre intelligible l’invisible ?
∞ —
Axes de travail
Axe 1
Les assistants vocaux empruntent dans leur version domestique les apparences de la transparence moderniste. Devant cette neutralité apparente et la simplification ultime de l’ergonomie (moins d’interface visuelle pour heurter la fluidité d’utilisation) l’utilisateur est amené à délaisser son sens critique.
→ Comment l’intervention des designers peut-elle permettre l’intelligibilité de ces techniques ?
Crispin Reedy, « Where's Jarvis? The Future of Voice Recognition », 2016
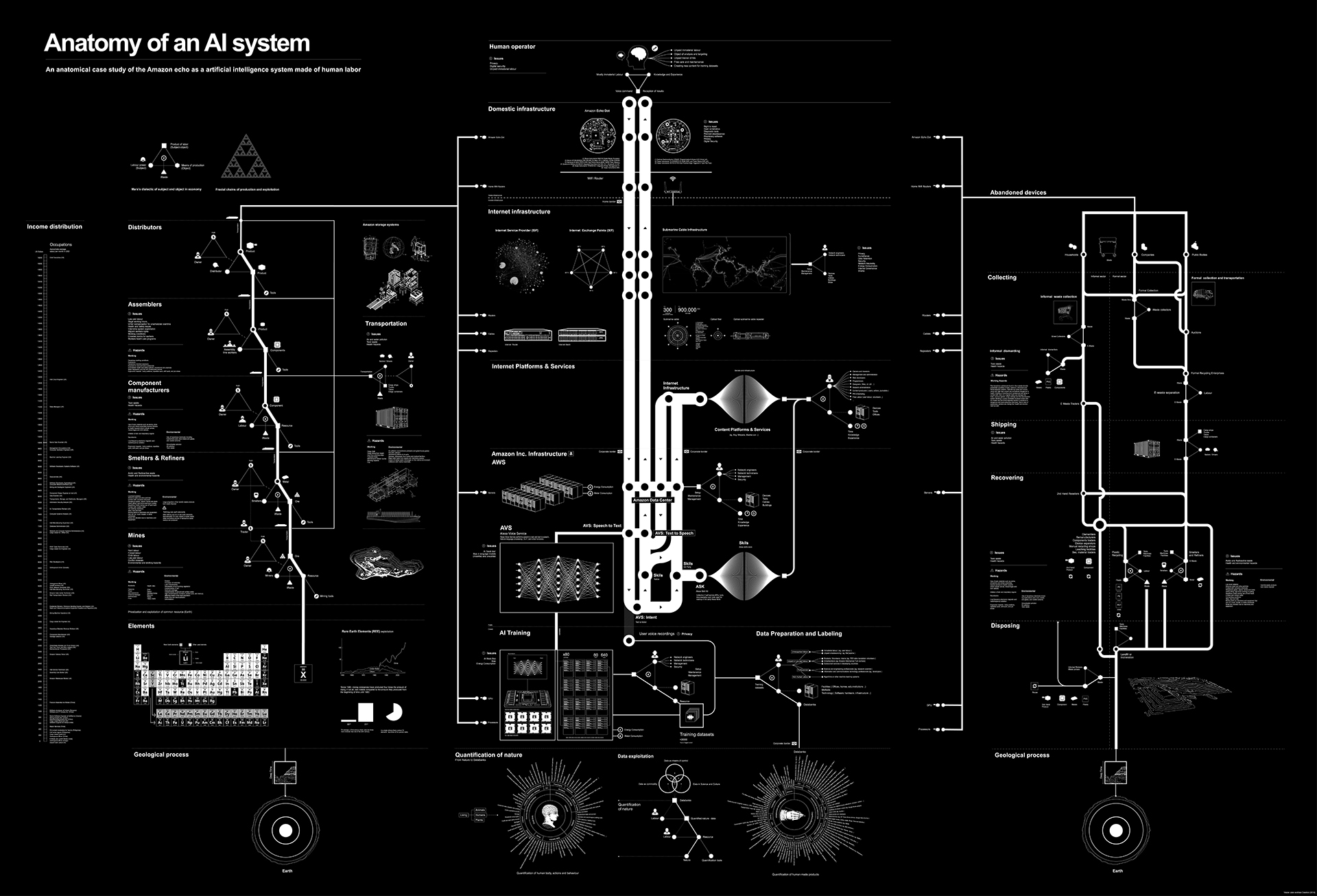
Kate Crawford, Vladan Joler, « Anatomy of an AI System » [Amazon Echo], 2018
Axe 2
La facilité d’utilisation des assistants vocaux masque de nombreux déterminismes dans le calcul des résultats des requêtes, qui se limitent souvent à un seul résultat dont le choix n’est jamais neutre. De plus, de nombreux cas interrogent sur la gestion de la vie privée et des données personnelles. Quelle ouverture des assistants peut-on envisager ?
→ Quelle « privacy by design » voire « attention by design » élaborer ?
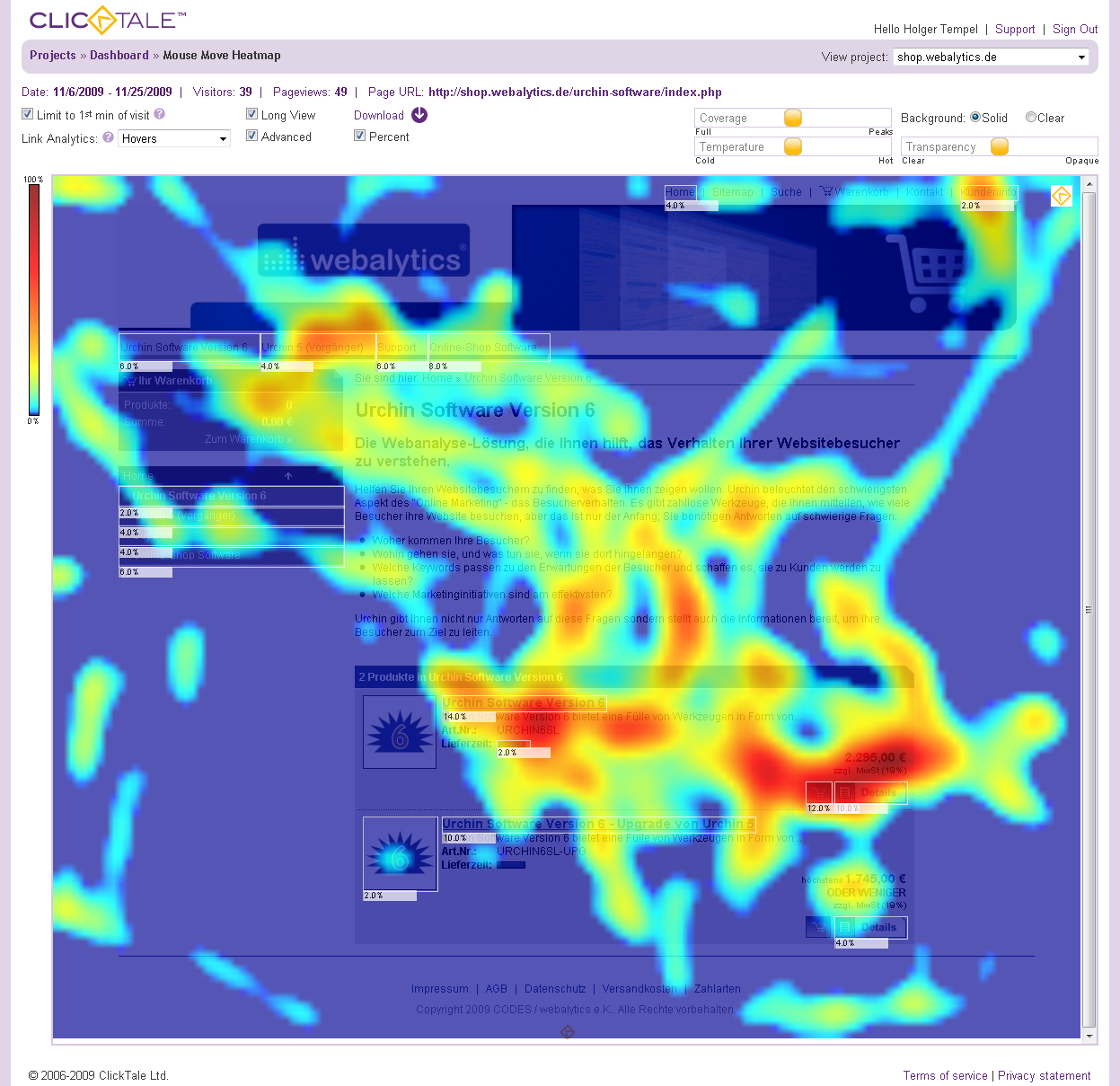
Web heatmap & analytics : l’économie des gestes et du regard
Adobe Voice Analytics, 2017
Axe 3
Les usages actuels des assistants vocaux sont très stéréotypés voire comportementaux : météo, scores de matchs sportifs, commande d’objet ou de nourriture, etc.
→ Comment subvertir (hacker) ces derniers ? Que peut-on inventer dans d’autres domaines actuellements peu couverts (création, fiction, accessibilité, recherche, etc.) ?
« Assistants vocaux : la menace du hacking à ultrasons », 2017
« Man hacks Alexa into singing fish robot, terror ensues », 2016

« Burger King fait parler Google Home, puis pollue Wikipedia », 2017
« Google et Disney s’associent pour des effets sonores sur Google Home », 2018
Axe 4
Les assistants vocaux sont la plupart du temps montrés isolément, séparés des objets et des espaces dans lesquels ils s’insèrent.
→ Comment les intégrer et les repenser au sein d’un système d’objets, au-delà des impasses de la domotique ?

Jarvis / Iron Man
« Zuckerberg lives superhero fantasy, builds his Jarvis after a year of coding »
Axe 5
Dans les usages actuels, les interfaces vocales tendent à exclure complètement toute approche visuelle. La voix, celle de l’usager comme celle de l’assistant, devient le seul élément sensible de l’interface.
→ Quelles possibilités existe-t-il dans les complémentarités d’une interface visuelle et d’une interface vocale ?
« What If You Had An IA for Photo Editing? », Adobe Sensei, 2017
« Rencontres du troisième type. Écrire avec des images », ANRT Nancy, 2018
Raphaël Bastide, Unilist

« Integrating emojis in a font », Black Foundry, 2017

Fonte variable Vesterbro (Black Foundry), 2017

v-fonts.com (Nick Sherman), 2018

« Antique Gothic sound sensitive specimen », Prototypo, 2018
Axe 6
La perception vocale représente une partie infime des possibilités offertes par le sonore. Les voix proposées par les assistants vocaux restent une imitation synthétique de la voix humaine, dans la prosodie, dans le ton.
→ Quelle variété dans les intonations, les silences, les hésitations peut-elle être autorisée dès lors que la vocalisation automatique se permet l’indécision ?
Axe 7
En oubliant le mimétisme avec la voix humaine, l’intervention du designer sur les interfaces vocales pourrait être conséquemment élargie, accordant un espace inattendu d’exercice du design sonore.
→ Que reste-t-il d’un assistant vocal qui a perdu sa voix ?
Résumé des axes de travail
- 1 — Rendre ces techniques intelligibiles
- 2 — « Privacy by Design » et « Attention by Design »
- 3 — Subvertir et ouvrir les usages stéréotypés
- 4 — Penser un système d’objets élargi
- 5 — Associer des interfaces visuelles et vocales
- 6 — Travailler les multiples variations de la voix
- 7 — Penser l’interaction sonore au-delà de la voix

@AnthonyMasure
www.anthonymasure.com
—
Présentation conçue avec Reveal.js, MIT License
Crédits typo : IBM Plex, Mike Abbink / Bold Monday, 2018
Image de début : Dave Whyte, 2014
Image de fin : Olli Meier et Bernd Volmer, TYPOLabs, 2018